စာမေးပွဲနား နီးလို့ ထင်တယ်။ စာက မဟုတ်ရင် ကျန်တာအားလုံး လုပ်ချင်နေတယ်။ လောလောဆယ် လုပ်ချင်နေတာကလဲ Coding ပိုင်းပဲမို့ စာနဲ့တော့ ဆိုင်မှာပါလေ လို့တော့ တွေးထားတာပဲ။ >.<
Social Network ဇာတ်ကားအကြောင်း ခေါင်းထဲရောက်နေတော့ အဲဒီထဲအတိုင်း လိုက်လုပ်ကြည့်မလို့။ ဒေတာ scrape တဲ့ process ကို ချရေးမလို့လေ။
ဇူလိုင် ၁၅ – မနက် ၁၂ (သို့) ၁ နာရီ
ဒီ ဒေတာ စုဖို့ idea က ရတာ ကြာပြီ။ ဒါပေမယ့် ဒီနေ့ည စိတ်ရူးပေါက်မှ ထလုပ်မယ် ဖြစ်သွားတာ။ ဒေတာတွေ ဘယ်က ရနိုင်မလဲ စရှာကြည့်တယ်။ စိတ်ကူးချိုချိုကတော့ စာမျက်နှာ ရာဂဏန်းပါတဲ့ စာအုပ်စာရင်း တင်ပေးထားတာ တွေ့တယ်။ ဒါပေမယ့် scrape လုပ်ဖို့ အရမ်း မလွယ်လောက်ဘူး။ အဲဒါနဲ့ website တွေကို လျှောက်ကြည့်ရင် WE ရဲ့ chatbot ကနေ ဒေတာယူဖို့ စစဥ်းစားမိတာ။
အစက chatbot ပုံစံကနေ ဒေတာယူမှာဆိုတော့ မဖြစ်နိုင်လောက်ဘူး(အရမ်းခက်လောက်တယ်) ထင်နေတာ။ ဒါပေမယ့် API access ယူလို့ ရတာ ရှာတွေ့တယ်။ Response က HTML format တော့ ဖြစ်နေတယ် ။ JSON မဟုတ်တော့ အလုပ်တော့ ရှုပ်မှာပေါ့လေ။ ဒါပေမယ့် Requests-HTML library လောက်နဲ့ဆို အဆင်ပြေပြီ ထင်တယ်။ လုပ်ကြည့်မှ သိမှာပဲ။
အခု မနက် ၂ နာရီ ထိုးနေပြီ။ ဘယ်လောက်ထိ ပြီးနိုင်မလဲ။
2:16 AM
environment setup ပြီးပြီ။ author ကနေ စပြီး scrape ရမယ်။
3 AM
နာမည် နဲ့ id ရဖို့ကို တော်တော် လုပ်လိုက်ရတယ်။ bs4 သုံးရတယ်။ မသုံးတာကြာပီဆိုတော့ ဘာတွေမှန်း မသိတော့ဘူး ။ အယ်လယ့် ။ မဟုတ်ရင်တော့ သိပါတယ်ပေါ့။ Official documentation is the best!!!!!
3:38 AM
author id နဲ့ name အတွက် json ရပီ ။ စုစုပေါင်း ၁၆၅၀ ယောက်စာ ရတယ်။ ဟုတ်/မဟုတ်တော့ ကိုမြေမှုန်လွင် သွားမေးမှ ထင်တယ်။ >.< ။ စာရေးဆရာနာမည်တွေမှာ character code တွေ ပါနေတာတော့ ပြန် clean ရဦးမယ်။ ဒါပေမယ့် စာအုပ်စာရင်းအတွက်က id ပဲ လိုတာဆိုတော့ လောလောဆယ် အဆင်ပြေသေးတယ်။
4:10 AM
JSON write ထားတာမှာ မှားတာကြောင့် ထင်တယ်။ ပြန်ဖတ်တဲ့အခါမှာ List of Dictionaries ကနေ error တွေ တက်နေတာ။ json dump နဲ့တော့ ပြန်စမ်းနေတယ်။နောက်ပြီး JSON standard မှာ double quotes နဲ့မှ အမှန်တဲ့ ။ အစက single quote တွေနဲ့ သုံးထားတာ။ :’)
json dump သုံးရင် str ပြောင်းစရာ မလိုဘူး။ Reference . ပြန် run ရပြန်ပီ ။ :’)
4:21 AM
နောက်ဆုံးတော့ JSON ထဲကို unicode အနေနဲ့ မှန်မှန်ကန်ကန် ရေးထားပီး List of Dictionaries အနေနဲ့လဲ မှန်မှန်ကန်ကန် ပြန်ဖတ်လို့ ရသွားပါပြီ ခင်ဗျာ။
4:25 AM
book api မှာက pricing တွေ cover image တွေ ပါတယ်။ စာရေးဆရာ နာမည် လဲ ပြန်ပါတယ်။ image ကိုက လောလောဆယ် url အနေနဲ့ပဲ ယူထားတာ ကောင်းမယ် ထင်တယ်။ နောက် လိုအပ်မှ ပြန် download ဆွဲလို့ ရရင် ရပီ ဆိုတော့။ grid item တစ်ခုချင်းဆီ ယူပီးမှ တဆင့်ချင်းဆီ ဒေတာ ရှာယူရမယ်။
6:09 AM
အားလုံးနီးပါး ပြီးပါပြီခင်ဗျာ။ Author ရှိသမျှ loop ပတ်ပြီး csv/parquet အနေနဲ့ပဲ ထုတ်ဖို့ ရှိပါတော့တယ်။
6:30 AM
အခုထိ loop ပတ်တာ ထိုင်စောင့်နေရတုန်းပဲ။ အဲဒါကြောင့် Time Complexity + Data Structure က အရေးကြီးတာ။
8AM
အပြင် မုန့်ဟင်းခါး သွားစားပီး ပြန်လာတော့ ဒေတာ ၄၀၀၀ ကျော်နေရာမှာ terminal မှာ run ထားတာက ဆက်မလုပ်တော့ပဲ ရပ်နေတယ်။ အဲဒါနဲ့ ရပ်လိုက်ပီး sqlite ထဲကို loop တိုင်းမှာ backup အနေနဲ့ append လုပ်တဲ့ အပိုင်း ထပ်ထည့်ပြီး ပြန် run လိုက်တယ်။ နောက်ရက်တော့ ဒီလို motivation နဲ့ နောက်ထပ် site တစ်ခုပေါ့ ။
ဇူလိုင် ၁၅ – ညနေ ၄ နာရီ
အခုထိ ကောင်းကောင်းမအိပ်ရသေးဘူး ။ ဒါပေမယ့် သွေးကြောထဲမှာ ဇူကာဘတ် ပိုးတွေ စီးဆင်းနေပုံရတယ်။ 😀 နောက်ထပ် website တစ်ခု ထပ်တွေ့တယ်။ အမှန်က အခြား website ကို ကြည့်နေတာ။ JQuery တွေ AJAX တွေနဲ့ scrape ရမယ့်ပုံ ဆိုတော့ ရှုပ်ယှက်ခတ်နေတာနဲ့ စိတ်ပျက်လက်ပျက် နဲ့ ဒီ website ကို ရောက်တယ်။ အားနာစရာကောင်းလိုက်အောင် wordpress json api ကနေ ခေါ်လို့ ရနေပီ အဲဒီကောင်ကလဲ request တစ်ခုချင်းဆီကို max item 100 နဲ့ loop ပတ်ပီး ခေါ်လို့ ရနေတယ်။
အရမ်းမခက်လောက်ဘူး။ ဒေတာ ၄၀၀၀ ကျော်လောက် ထပ်ရနိုင်တယ်။ bs4 တောင် မလိုလောက်ဘူး။ requests lib နဲ့တင် လုံလောက်လောက်တယ်။ Okei, let’s do it. For wordpress API , check under header to see the total.
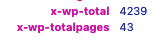
4:15 PM
ပြဿနာတော့ စပီ။ စျေးနှုန်း ဒေတာက api ထဲမှာ မပါတာလား? product page link ပါတယ် ဆိုတော့ bs4 နဲ့ parse ပီး ယူလို့တော့ ရတယ်။ လွယ်တယ်လို့ အပြောစောသွားတယ် ။ :’D
7:15 PM
ပြီးတော့ ပြီးတော့မယ်။ loop ပတ်ပြီး df ထဲ ထည့်ပြီး sqlite ထဲကို append လုပ်ဖို့ပဲ ကျန်တော့တယ်။ တစ်ခု စိုးရိမ်တာက api response structure ပြောင်းရင် code ကတော့ error တက်မှာပဲ။ အထူးသဖြင့် author tags မှာ 0 အပြင် အခြား 1,2,3 ဆိုပြီး ဝင်လာမှာကို စိုးရိမ်တာ။
7:55 PM
အပေါ်က စိုးရိမ်တဲ့အတိုင်း တကယ် ဖြစ်ပါတယ်ခင်ဗျာ။ လောလောဆယ်တော့ number_of_authors ဆိုပီးပဲ ယူထားလိုက်တယ်။ ပြီးမှ 1 မဟုတ်တဲ့ ဒေတာတွေ ပြန်လိုက်စစ်လိုက်တော့မယ်။
8 PM
result ရပီ ။ စာအုပ် ၄၀၀၀ ကျော်ဒေတာ ထပ်ရလိုက်တယ်။
You must be logged in to post a comment.