Today writing is my current project wrap-up and also English writing practice. It had been over a week I was being attached to that project (Burmese OCR) and still trying to break away by finishing it.
The beginning of this project is – in the Burmese language, we don’t have proper table extractor application like Tabula. During this November, we got tons of pdfs, images & papers from the Government related to the November 8 election and COVID-19 stats. So, when we wanna digitize these documents, most of the time is the manual way. It’s repetitive & boring. So, I wanted to change that condition, since a long time ago.
I’ve never had experience in Image Processing (like using OpenCV), so it’s too far for me to make table detection, then extract words. But the initial start is when I read Fazlur Rahman‘s blog post – Text Extraction from a Table Image, using PyTesseract and OpenCV. That article is a really helpful & systematic guide for me. I followed the instructions and repeat to read it again & again when I got difficulties. The important lesson I learned here is when you’ve to follow a complete guide, you must not be happy for just getting output results. You must think the insights – why he used that method in here, why he put this process in this code, how this code is implemented – like trying to read the writer’s thoughts & mind. That made it easier when you faced unexpected errors (that won’t be mentioned in the guide). Most of these errors can be fixed easily by correcting minor cases when you realized the process as the writer.
Even Rahman describe the process clearly , it took me a night to do the same as his tutorial. After getting the same results as him , I tried to change the images from using example images to the real Burmese table images. Then , the storm began. I listed down what I would like to do in my application.
1.Line detection but different layout in my images.

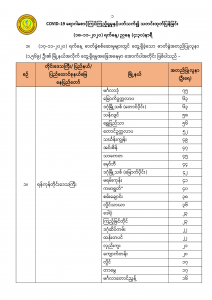
2. Burmese OCR with Tesseract dataset
Another big, big problem that I faced is the lack of good quality datasets for Burmese words. When I check trained data on Tesseract, the last support for the Burmese langue is 3 years ago and then that dataset is wrong as combining Unicode & Zawgyi fonts. We may need to train a better quality one. I tried to read the tesseract training process. It’s a little complex (for me). So, I gave up for now, but think about trying later when I have time. That may become good support for our language improvement.
So, right now , even my code detect the lines & table correctly , the result isn’t too good. Getting wrong translation in words , especially for Burmese numbers.
3. Folder input
In Rahman’s example, he showed only one image as a direct import. But, in mine , it must be worked for the folders. Because in Gov’s daily announcement, the images are at least 4 or 5. So , when I combined the data in weekly, monthly order, I need to complete in one command. To change the code to work for the whole folder, this project repo by pndaza is really helpful for me. His project is similar to mine. He’s also doing for Burmese OCR, but for the paragraph format. He used folder input in his code, it became a helpful reference.
4. Multiple Images mean multiple shapes/formats while Table Detection
When I put multiple images into my code , it didn’t work for the first time. Because even I tried to crop the images as the same , the columns & rows conditions are different from each other. So I need to re-write my code (that works for one image/format) to change flexible code that works for different formats. It took most of my time because I’ve never familiar Image Processing algorithms like Hough Transform and also OpenCV functions like Canny.
That’s the most difficult part for me. Even I got a good result at the end, I admit that I still need to read a lot of things that I skipped and didn’t understand.
The overall process for table detection in different formats – as my understanding –
- Must detect the vertical lines & horizontal lines correctly, then must count exactly
- I tried to get the column/row index, then the last column & the last row as below one.
horizontal, vertical, last_row, last_column = detect_lines(src, threshold = 150, minLinLength=150, display=True, write = False)– from folder_input.py- Important fact – need to know how to tune threshold & minLinLength values.
- Getting cropped images correctly
5. Link with Google Sheets
I used gspread & gspread_dataframe libraries to connect with my google sheets.
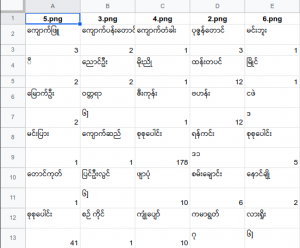
I still need to play more with Python Pandas & Python Dictionary structure to get more reliable result in DataFrame or CSV.
Then I’m planning to make a record video for the whole project,definitely sure will forgot how I wrote that come in a few months. And also complete detailed project documentation.
My code is already published to Github – here. All my purpose in writing this blog is I would like to say special thanks to Rahman and other contributors who lead me to reach that level and encourage me to learn new things. I won’t ever forget that project, the first-ever time I went through day & night thinking about this, getting nervous while errors, having fun when getting solutions & output.
Leave me messages in here if you had something to know more Burmese OCR. I’ll try to contribute back as much as I learned. Thanks for giving your time to read the article completely.
You must be logged in to post a comment.